

Call me a nerd (you wouldn’t be the first), but I am fascinated by metadata.
For years, I have been thinking about the importance of organizing our content on the CMI website so people can find what’s most important to them instead of what’s most recent, and I know metadata is the key to this. (In fact, I often think about this post from Doug Kessler on what he referred to as library marketing waaaay back in 2010.)
Of course, content strategists have been organizing content for decades (it’s just one of the things content marketers can learn from content strategists), and I have been determined to learn more.
Fortunately for me, Rachel Lovinger, an expert on all things metadata, offered to answer several questions for me. Here are the top things I learned.
Metadata reveals connections within your content
Let’s start from the beginning. We have all heard the term metadata, but what is it – and, more importantly, why do marketers need to care? Rachel filled me in on the basics.
Metadata is information that expresses context and meaning about something. For example, when you show me a photo of yourself eating ice cream, I can see that it’s you eating ice cream, but I may not be able to tell where you got it, what flavor it was, what time of year it was, who took the photo, and other things like that unless you explicitly tell me.
Metadata helps content creators provide better connections so they can reveal related content to their audience, and it makes those connections much more precise.
Blog categories and tags are two kinds of metadata; there are others
When I think of metadata, I immediately think of blog post categories and tags. But is this the only kind of metadata I should be concerned with? Rachel breaks down the various types (and explains the difference between categories and tags).
Categories and tags are two ways of editorially assigning metadata to blog posts (or any other type of content).
Tags tend to be focused on topics, such as: SXSW2015, Taylor Swift, Tube Strike. They’re flexible and can expand to cover whatever topics are of interest at any given time, allowing people to add new ones as needed. Think of tags as equivalent to hashtags and trending topics on Twitter.
On the other hand, categories should be more organized and planned out. In fact, when a blog uses both categories and tags, the set of categories is generally much smaller than the set of tags. They can be used to capture a variety of things. For instance, categories can be:
- Topics (such as Politics, Sports, Entertainment)
- Content types (such as News, Review, Interview)
- Formats (such as Video, Photo Gallery)
Metadata applies to more than blog posts. Other types of metadata, aside from categories and tags, might be automatically created by the system that’s being used to generate the content, for example, the author’s name or the publication date. Often referred to as “administrative” metadata, this type helps establish the credibility and source of some content because it’s assigned by a system so it’s less prone to user error or tampering.
 THANKS TO ONE OF OUR INTELLIGENT CONTENT SPONSORS:
THANKS TO ONE OF OUR INTELLIGENT CONTENT SPONSORS:
New Global Research – Rating the Content Quality from 170 Companies
Download the full report to learn:
–How 170 brands rate for content quality and consistency
–What is the connection between content consistency and performance
–What types of content (product, support, blogs etc.) have the highest (and lowest) quality
There is no right amount of metadata
I have worked on CMI’s taxonomy (i.e., the primary categories or our content) for years, and I find myself tweaking things. I don’t want too many categories as it’s tough to keep track of all of them. But, if I have too few, is that useful enough? Rachel explains how to find that balance.
If your primary focus is SEO, there are probably best practices about how many keywords are necessary to make an impact and how many are “too many.” From a user experience perspective, you want to strike a balance between functionality and effort.
If you have too little metadata, it won’t support the things you want to do with your content – or the things you want to enable your users to do. So, it’s critical to determine your business goals and then consider what metadata you will need to enable those goals.
For example, I worked on a project that aggregated photos of home-decorating approaches into a gallery that was browsable by the top-level categories Rooms, Room Detail, and Solutions. By making the appropriate metadata visible to the end user – part of the interface – we helped people navigate to the photos they wanted to see, and we encouraged them to browse by clicking links to similar photos.
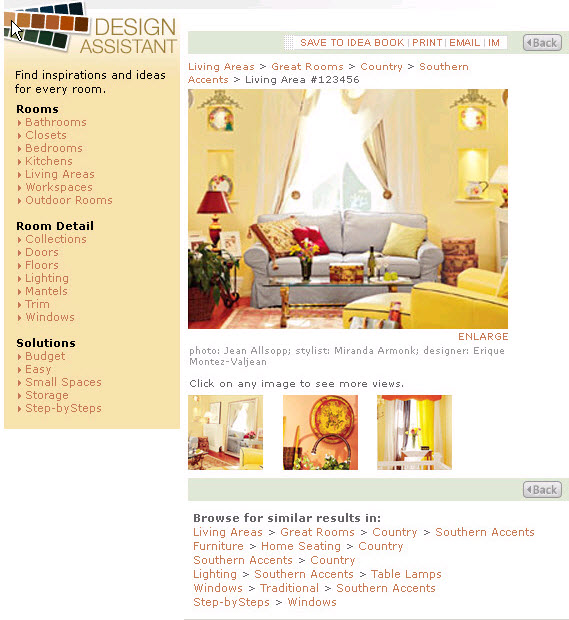
For this site (which is no longer live), we incorporated metadata into the user experience in a way that supported our goal of inspiring people. For example, in the navigation panel on the left, the clickable metadata categories – Bathrooms, Doors, Small Spaces, etc. – are grouped under three top-level categories: Rooms, Room Detail, and Solutions. At the bottom, the “Browse for similar results” links are also generated by metadata.
It takes thought to figure out how many categories to create and what they should be. For example, under Room Detail, a category called Floor wouldn’t help anyone because every room has a floor; this category wouldn’t help people find similar photos. However, if you saw a beautiful photo of a wood floor, you might want to see more images with that feature, so we created a Wood Floor category.
If you try to apply too much metadata, your staff may not be able to manage the content effectively and you’ll end up with gaps or inaccurate content. The more detailed your metadata is, the more effort your team has to put into making decisions about which category to use. If making those distinctions isn’t providing value, then this is wasted effort.
For instance, in the home-decorating example above, we initially took our taxonomy a level deeper under Wood Floors – we had subcategories like Bamboo Floors, Cork Floors, and Hardwood Floors. The problem was, we didn’t have a volume of content that required making that distinction, and it wasn’t always clear what type of wood was featured in the photos, so subcategorizing to that level ran the risk of confusing our content producers. They might have ended up assigning categories inconsistently or incorrectly – some applying both Wood Floors and a subcategory (like Hardwood Floors), others applying just the higher-level category Wood Floors, others applying an incorrect category based on their best guess, still others applying no category if they didn’t know which one was correct.
Besides, since the gallery was designed primarily to provide inspiration, not for the purchase of flooring materials, we had no reason to believe that our audience wanted or needed that level of detail. Eventually, we removed those more specific terms and just stuck with the higher-level category Wood Floors.
Amazon is an ideal example of metadata in action
There is often no better way to understand something than to have an example of it. I asked Rachel for her favorite example of a website (brands preferred) that incorporates metadata to improve a visitor’s or customer’s experience.
It’s not always easy to tell what metadata a site is using unless you worked on it, but it’s safe to say that any site with robust navigation or personalization has a thorough set of metadata behind it. For example, most of us probably go directly to search when we go to Amazon. If you type in a term like “yoga mat” and you don’t see exactly what you’re looking for in the results, you probably go to the left side where you’ll see a bunch of categories and filters that will allow you to narrow the results.
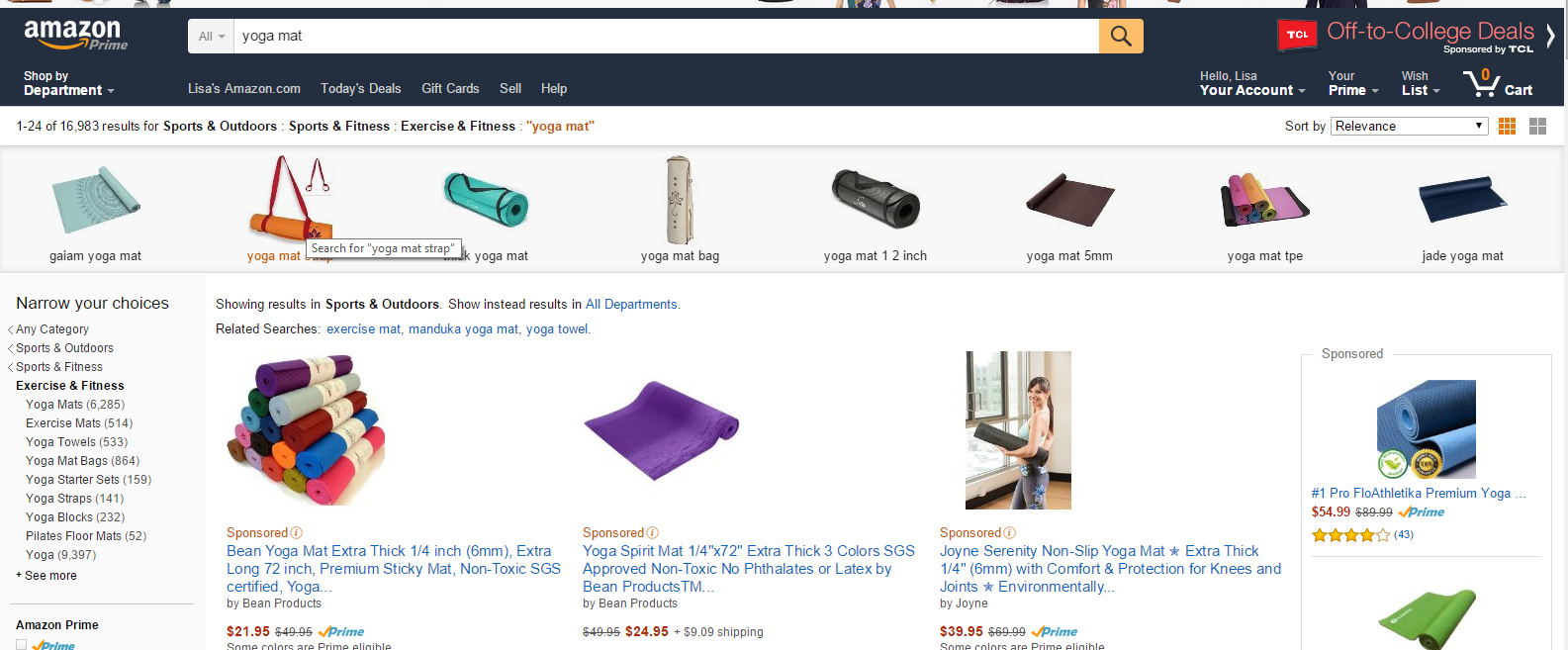
All of those categories and filters – which some people call a faceted search – are driven by metadata. And of course, all the related recommendations (for example, items listed under the headings “Recommended for You” and “Customers Who Bought This Item Also Bought”) are driven by metadata as well, including metadata about past products you’ve purchased from them.
Building metadata is a team effort
I know how tough it is to come up with a standard set of categories. And, with tags, it’s really difficult to keep everyone using the same tags consistently. What is the best way to come up with a standard set of categories (which ideally becomes relatively stable) as well as a process for applying tags (since tags, as noted above, “tend to be more expansive, allowing people to add new ones as needed”)? Rachel has a few ideas.
I start by analyzing the existing content and metadata. If you have a variety of terms that need to be normalized and merged into a more coherent organization, you may want to do some card-sorting exercises. In essence, card sorting is an approach from the user-experience discipline where you talk to users to find out how they would categorize your content. If you want to learn more, I recommend Donna Spencer’s book, Content Sorting: Designing Usable Categories.
It’s also useful to get stakeholders involved in these exercises. They can help you understand why certain words were used instead of others, and they’ll feel more invested in using the metadata if they were involved in defining the categories.
Here are some suggestions for getting your teams aligned:
- Conduct initial training on what the various metadata categories and tags mean and how they should be applied to content.
- Document guidelines for people to refer to later. Include information about how the categories and tags will be used on the site so that people understand the impact of not applying them properly. For example, in the home-decorating site, we let our content producers know that if the images weren’t categorized properly, site visitors would be unlikely to find them when browsing the gallery.
- Make sure people know what process to follow if they need to add a new category or tag. Otherwise, if they don’t find what they’re looking for, they may lose confidence and stop adding metadata to their content.
- All of this documentation should be made available to everyone who creates content, ideally on a wiki or similar platform where it can be updated as the system grows and evolves.
Getting consensus for metadata can be challenging
Of course, I don’t know what I don’t know when it comes to metadata. I asked Rachel to share some common struggles with metadata – as well as their solutions.
One of the biggest challenges I’ve seen, especially in large, complex organizations, is getting consensus. There’s no easy solution to this, but here are a couple of recommendations:
- Get stakeholders involved as early and often as possible. Make sure they understand the benefits of tagging their content so they don’t feel like you’re asking them to do extra work for no reason.
- Enlist the help of a dynamic and influential champion to show influential stakeholders the benefits of using metadata and participating in your project.
Of course, the difficulty in getting consensus isn’t unique to metadata projects, but since metadata is often most effective when it’s part of a coherent, well-thought-out system, issues may come to the forefront.
You can get help tagging your legacy data
Another thing that overwhelms me a bit about metadata is that it seems like a lot of work to go back and tag all existing content . . . especially if things may change in the future. Do I start with recent content and move forward? Or should I go through all of the existing content – and how? Rachel shared several good suggestions.
Text-based content
If we’re talking about descriptive metadata (think: tags instead of administrative metadata), there are tools that can read through your (text-based) content and extract concepts. You can then have people review and validate them. For example, there’s the Thomson Reuters Open Calais (TM) project, which drives a WordPress plug-in called Tagaroo. They also have an API so that it can be integrated with other publishing systems.
Non-text-based content
If your content isn’t text-based, you can try crowdsourcing the work, using something like Amazon’s Mechanical Turk, or just asking your audience to help. I know a web comic artist who asked his readers to help transcribe the comics in his archive. In a short time, they transcribed over 1,500 comics. Of course, it helps to have an engaged fan base if you’re going to ask for that kind of participation.
Content needing specialized knowledge
If tagging your content requires specialized knowledge or you need a greater level of accuracy for other reasons, you may have to hire some temporary resources to help clear the backlog, and then train your regular content producers to tag current and future content as they’re producing it. It’s a lot easier to do it at the time of creation than it is to go back later and add tags.
Metadata evolves; your plan needs to allow for changes.
As with anything to do with content, metadata needs to change over time. What is the best way to plan for these unknown evolutions?
Developing a metadata vocabulary is an ongoing project. It should initially be set up so that new terms can be added with minimal impact. However, the overall metadata structure shouldn’t change that often. Try to identify all the broad areas that you want to cover at the beginning so you can keep them stable while adding more detail into each area as needed.
For example, in the case of the home-decorating site described earlier, we used the top-level categories Rooms, Room Detail, and Solutions. These were the primary ways people would browse the gallery. Within that structure, the site owners could easily add a new decorating style – for example, Rustic – with minimal disruption. But if they were to decide, months after launch, that they wanted to change the structure by adding another top-level category by which to sort – for example, Color – the change would be a lot more complicated, requiring the site to be redesigned and requiring all the photos to be recategorized with the new color-related metadata.
To prevent metadata from growing out of control, you need a governance plan, to define how and when people can make changes to categories, tags, and other metadata. The same decision-making factors that go into creating the initial set of terms should be brought into play when deciding on changes.
If you need help with your metadata, consider a digital-savvy librarian
Many marketers need to understand the importance of metadata, but in many cases, they may not be the best person to create and implement this strategy. (We don’t need another thing on our list, right?) I attended Rachel’s session on metadata during Confab, and she mentioned they had hired a librarian for one of their taxonomy projects. It makes sense, but it’s something that would not have occurred to me. Rachel filled me in on how marketers can find the right help.
We were excited when we convinced our editor at Entertainment Weekly that we needed to hire a formally trained librarian. And we were super lucky to find Barbara McGlamery, who was working at the New York Public Library at the time. She was digital-savvy, so she was a great fit for us.
These days, I think a lot of people who study library science are approaching their work more from a digital perspective and are interested in a wide range of opportunities, not just working in traditional libraries. It’s probably a lot easier to find people with that sort of training and background who would enjoy working with digital content now than it was 15 years ago when we hired Barbara!
What questions do you have about metadata? How has your content marketing team benefited from using metadata in strategic ways? I’d love to hear about your experiences in a comment below.
Want more? Sign up for the Intelligent Content weekly email newsletter. When you do, every Saturday we’ll send you an email pointing to our latest posts on intelligent content and content strategy topics along with an exclusive letter from Robert Rose, chief strategy officer for the Content Marketing Institute.
Cover image by Joseph Kalinowski/Content Marketing Institute
