
Late in 2013, Scott Abel, The Content Wrangler, asked my company, XML Press, to collaborate with him and Rahel Anne Bailie to create a series of short, practical books about content strategy. So far, we have published five books in the series and have several more projected for publication this year. The first book in the series, The Language of Content Strategy, defines 52 essential terms for content strategists. That book brought together 52 experts, who each provided the definition for one term. From these definitions, we created five separate deliverables: print book, e-book, web, audio, and a card deck.
As a starting place, I suggest that you read Marcia Riefer Johnston’s overview of The Language of Content Strategy as a case study of content modeling, reuse, and responsive design. Then, if you want to get into the how, this article is for you. Here, I give you a peek into the technologies that support the project, especially those used to capture content and produce the project deliverables. (While this article focuses on The Language of Content Strategy, the same technology is also used for the other books in the series.)
Our requirements
From the beginning, a key objective of the project was to develop the book as its own case study of best practices in content strategy – to model what we preached.
Another key objective was to run the project on a modest budget, using open-source or inexpensive software as much as possible. While we realize that many projects have substantial budgets, we wanted to show that you don’t need a large budget to take advantage of these best practices.
With those objectives in mind, we developed these high-level requirements for the project:
- For each book in the series, create all deliverables—including print and e-book versions—from a single source.
- For The Language of Content Strategy, also produce a website and card deck (with each card containing one definition) from the same single source.
- Give contributors, editors, indexers, and production staff an easy-to-use interface that requires little or no training. (In practice, we wanted to make sure that contributors would need no training, and that editors and indexers would need little training.)
- Set up the website so that we could post one term per week for a year.
Note that XML was not a requirement. We used XML to help us satisfy these requirements, but the requirements could have been satisfied with other technology, too. (I go into this more under “Why we used XML,” below.)
Our content model
The Language of Content Strategy (the book) comprises a set of terms with definitions. The content under each term has the same structure, that is, the same elements with the same headings in the same order:
- “What is it?” – This section contains a short definition of the term.
- “Why is it important?” – This section contains a brief description of what makes this term important.
- “Why does a content strategist need to know this?” – This section contains a longer description of this term’s significance to content strategists.
- “Additional resources” – This optional section contains links to relevant material.
- “About the author” – This section contains a short biography of the author along with contact information.
All deliverables – the print book, e-book, web pages, audio recordings, and cards – were assembled from the same shared elements. Our content model looked something like this:
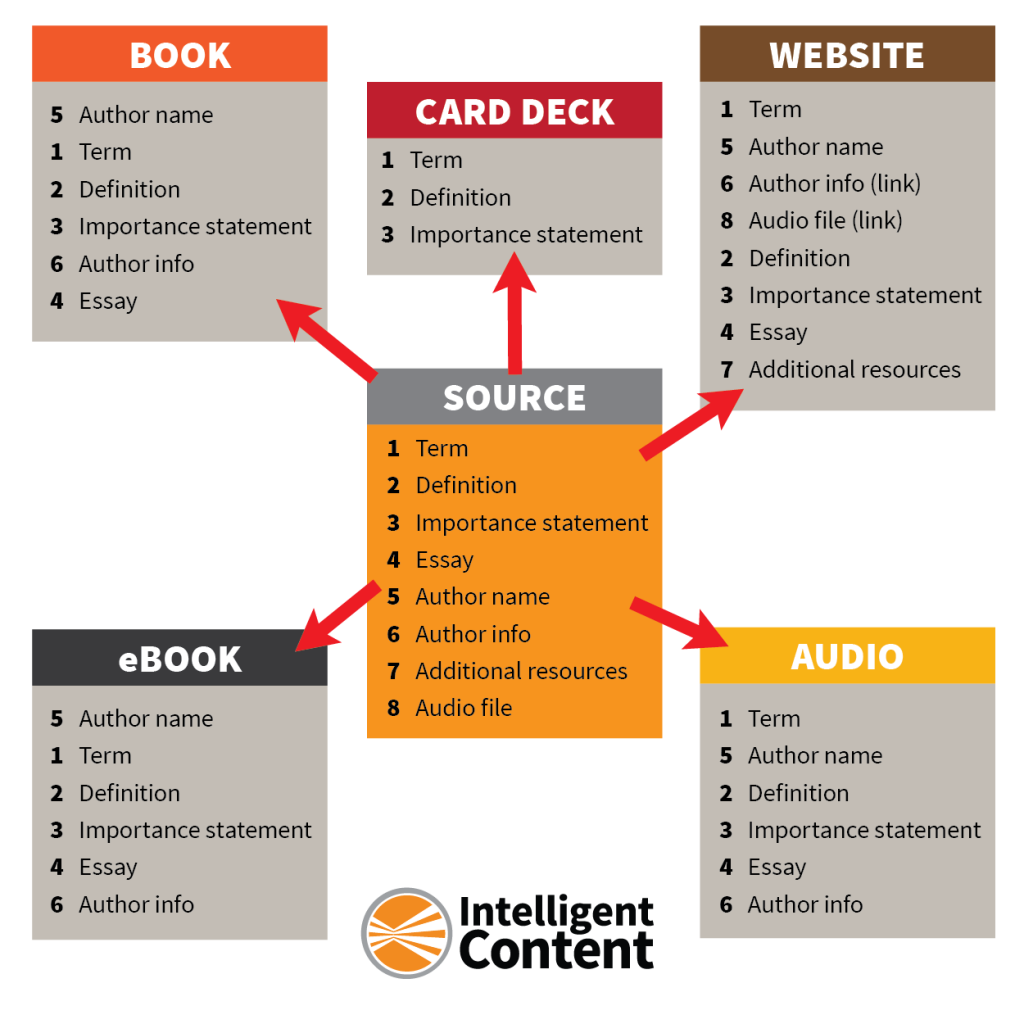
Figure 1. The Language of Content Strategy content model
Gathering input
Because 52 individuals contributed to the book, we needed to provide an easy method for entering content. We decided to use the Confluence wiki along with the Scroll add-ons from K15t Software, which add content management functions such as DocBook export and web publishing to Confluence. (I say more about the Scroll add-ons below.)
We started by creating a wiki template for contributors to use to input the information for their terms. The template provided the headings (“What is it?,” “Why is it important?,” etc.) and instructions (see Figure 2 for a screenshot of the template). Contributors just needed to log on and type. This worked well for most contributors, although a few gave us input in other forms for various reasons (such as trouble logging in or lost passwords). However, editors could accept emailed contributions. If this project was an ongoing one, we might have required some training to get all contributors working in the system.
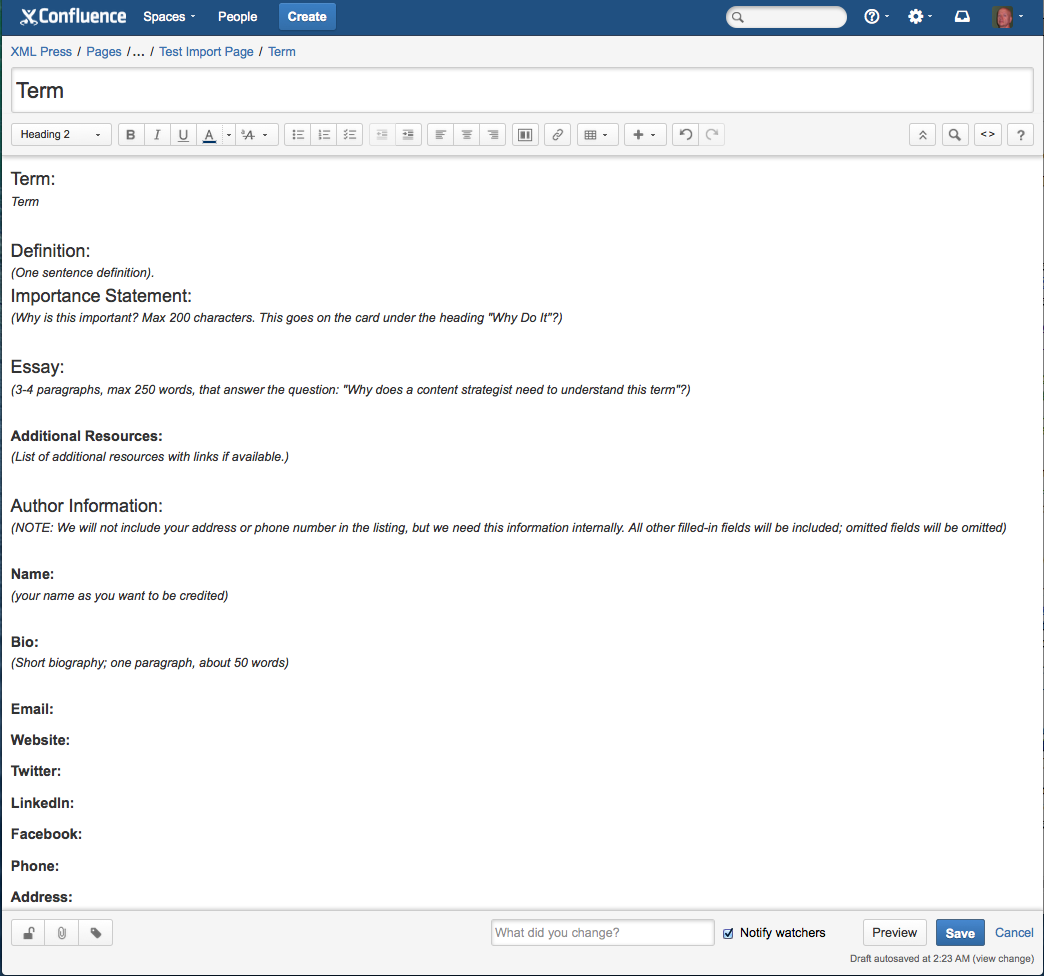
Figure 2: Screenshot of the wiki template
Because we were working in a wiki, we could track updates instantly, give authors immediate feedback, and track changes. We also gated access to help us better enforce deadlines and avoid the inconvenience of authors repeatedly coming back and tweaking their content after the deadline, which many authors are prone to doing.
The importance of using a single source
Confluence maintains content in a format that can be converted reasonably easily into different forms and supports add-ons for conversion to even more forms, including XML. We chose to keep the official source for The Language of Content Strategy in the wiki and only export it for deliverables. The wiki also serves as the website for the book. This means that any change to the source is immediately available to the website, which dynamically draws from the official source.
For example, when Val Swisher (who contributed the term governance model) published her book, Global Content Strategy, we changed her biography to show the book as published rather than forthcoming. That information became immediately available on the website.
In addition to the DocBook export add-on, the team at K15t Software also provided the Scroll Viewport add-on, which publishes content from Confluence as a website or blog, and Confluence macros that enable us to create web pages that pull just the content we need for each page, leaving behind the parts that we don’t need. In addition, they set up the look for the site and the capability that allows us to schedule posts to automatically appear weekly.
For all deliverables except the website, the source is exported to DocBook XML and processed using XSL stylesheets. Those stylesheets enable us to determine the format – the layout and look – of the deliverables and to determine which content elements will be included in which deliverable and in what order. And those stylesheets enable us to style links to match the format. (I would include a visual if I could; unfortunately, this part of the process is difficult to illustrate because it’s all command-line stuff that would be incomprehensible without a lot of explanation, even to a technical audience.)
Why we used XML
The acronym XML stands for eXtensible Markup Language. XML is an international standard for marking up data in a structured manner. XML provides a template for building specialized markup for tasks ranging from emergency planning to database systems to music notation to websites and much more. HTML is a close relative of HTML markup, sharing its angle brackets (< >) and other characteristics.
DocBook XML is an XML markup for creating books. It is commonly used for technical documentation and supports all of the elements you would expect in documentation (lists, tables, procedures, API references, etc.). While other technologies could have satisfied our requirements, I see XML as the most comprehensive and flexible standard for single-source publishing available at this time.
Deliverables
This project’s deliverables include a printed book, e-book, website, and card deck. In the print book (as shown in Figure 3), the definitions are laid out in a two-page spread. The pages have a consistent layout with the same structure. On left-facing pages, we see the author’s name (Rahel Anne Bailie), the term (content strategy), “What is it?,” “Why is it important?,” and About [author name].” On the right-facing pages, we see “Why does a content strategist need to know this?”

Figure 3. Example page spread from the print book
The cards (as shown in Figure 4) include a subset of the elements that appear in the print book, and the headings are customized for the smaller format. So the structure varies from one deliverable to the next. But from one card to the next, the structure is the same.

Figure 4. Example card
In other words, while the content is a single source across the various deliverables, it is not presented the same way every time. Examples:
- The e-book has the same structure as the print version except that the “About [author name]” section appears immediately after “Why does a content strategist need to know this?” instead of immediately before it.
- The “Additional resources” section does not appear in print for aesthetic reasons as well as usability (the links would not be live). This section does appear on the website.
- Cards use only two elements: “What it is” and “Why do it?” The body text in those sections is identical to the books, but short versions of the headings are swapped in programmatically.
You can see the web page for the same term in Figure 5. This web page contains more than either the book or the card deck. It contains an image of the author, the “Additional resources” section, and a link to an audio version of the term and its definition. Plus, there are “share,” “comment,” and “buy this book” links such as you find on most product web pages./////

Figure 5: Web page for the term content strategy
Creating the deliverables
With the exception of the website and audio, all deliverables were generated from DocBook XML exported from the wiki. For The Language of Content Strategy, all processing after the export is fully automated, which means that there was no manual tweaking of the output. For the other books, we migrate the single source to a DocBook XML repository and make that the official source. This allows us to have more control over the fine details of printed output, for example tables, figures, and typographical details. With The Language of Content Strategy, we didn’t have tables or figures, and the structure was regular.
That regular structure enabled us to automate the production of all deliverables.
Exporting to DocBook XML
The decision to use DocBook XML, rather than the arguably more popular DITA or some other markup, was purely pragmatic. XML Press has used DocBook for years and has customized the DocBook stylesheets extensively. DocBook gave us all the capabilities we needed and allowed us to draw on a body of existing stylesheets for both print and e-book deliverables. We could have done what we did with DITA, S1000D, TEI, HTML5, or any number of other XML schemas. All of them provide the basic capabilities we needed. However, any one of them would have required significantly more work without providing any useful benefits over DocBook for us. Of course, an organization that has extensive experience with another schema might logically come to another conclusion.
The first step for generating the book, e-book, and card deck was to export DocBook from the wiki. For that, we used the Scroll DocBook Exporter add-on from K15t Software. The team at K15t has created an exporter that converts all of the commonly used structures into DocBook, including tables, figures, headings, and inline markup. We then added a few things using specialized markup that authors, editors and indexers can use, including extended indexing capabilities and epigraphs.
Building the print book
For the print book, we created a fixed structure, as shown in Figure 1. Every definition fits on a two-page spread. Scott and Rahel edited each definition to fit this structure, although providing guidelines to contributors made editing for length minimal. The stylesheets then fit the text into the allotted space and set the parameters of the style (fonts, margins, colors, spacing, etc.).
By keeping tight controls over the text, we were able to generate a print-ready PDF from the wiki in an automated manner.
The DocBook stylesheets generate an intermediate language called FO, which is then rendered into PDF using XEP from RenderX.
Building the e-book
For the e-book, most styling is done through CSS stylesheets. The DocBook XSL stylesheets generate the basic e-book content, and CSS stylesheets apply styling to that result.
For other books in the series, we also need to generate bitmap images and size them correctly. The DocBook markup allows you to specify different images for different output types so we still maintain a single source, but that single source uses conditional text to select the correct image for each output type.
The eBook is generated in two formats:
- ePub, which is used by nearly every e-book reader except Kindle
- Mobi, which is used by Amazon’s Kindle
The ePub format is generated directly by the DocBook stylesheets. The Mobi format is generated from the ePub using a utility called Kindlegen, which is supported by Amazon.
Building the card deck
The company building the card deck needed input in InDesign format. To generate the InDesign, we worked with Charles Cooper of the Rockley Group. XML Press created a custom XSL stylesheet that pulled just the three things needed for the card (term, definition, and “Why is it important?”) and created an XML file that contained this information. Charles then pulled that information into InDesign, styled it to match the card deck print requirements, and sent it to the printers.
Creating the audio files
The audio was created directly from the source. However, the audio format required some minor rewording. For example, when reading headings, extra information was added to help set context. So, instead of reading “Term of the Week: Governance Model,” the voice actor would read, “The content strategy term of the week is the extended deliverables term, governance model.” The actor adds context, including information about the section of the book (Extended Deliverables) that the term comes from. When you read the book yourself, you don’t need this extra context because you can see the rest of the page. However, if the book were to be read without that context, the result sounds strange at best and incomprehensible at worst.
Creating the index
The index was created through two mechanisms:
- Automated index entries were generated for each term and for each contributor. This automation relieved the indexer of dealing with those entries and also enabled us to create a separate Contributor Index.
- The indexer created a standard index by embedding index entries into the text of the wiki. These entries are then converted into DocBook index terms using an automated script.
These mechanisms enabled the indexer to work in the wiki along with the editors and contributors. The DocBook stylesheets generate the back-of-the-book index using the embedded index terms.
Setting up a master glossary
The Language of Content Strategy is itself a glossary, so we decided to draw on it for the glossaries of other books in the series. To do this, we used an XSL stylesheet—XSL is a language that can be used to process and format an XML document—to pull these terms and their definitions from the common source and generate a DocBook glossary database.
Authors of any book in the series can create their own glossary by simply highlighting the terms they want in their books. The production software then grabs the glossary entries for each of those terms and creates a glossary specifically for that book. If an author has a slightly different definition for an existing term, he or she can easily substitute that definition for the one in the database. And, when any author creates a new glossary term, that term is added to the database for other authors to use.
Figure 6 shows the first page of a glossary that includes both terms from The Language of Content Strategy (such as content, content brief, and content model) and unique terms (such as analytics, content experience, and controlled vocabulary) from Kevin Nichols’ book, Enterprise Content Strategy: A Project Guide, another book in the Content Strategy series.

Figure 6: Excerpt from our glossary
Summary
We set out to use a single-source methodology and an intelligent-content strategy for the Content Strategy series. The result is a book series that minimizes effort for authors, maximizes reuse of both content and production software, and provides a valuable resource for readers.
Learn more
- A Case Study in Intelligent Content: The Language of Content Strategy by Marcia Riefer Johnston
- Content Models: Getting Started with Structured Content by Natalya Minkovsky
- Atlassian, developers of the Confluence wiki
- The Content Wrangler Content Strategy Book Series
- DocBook: The Definitive Guide, by Norm Walsh
- K15t Software, DocBook export software and wiki customization
- The Language of Content Strategy website
Title image and content-model drawing courtesy of Joseph Kalinowski, Content Marketing Institute
